
Overview of text mining procedures applied on the materials domain
The text mining process is a well-known synthesis task that can be applied on different texts. For instance, in the materials domain, it is a useful tool to find hidden relationships, predict new material candidates, or extract relevant information from materials science articles. As a more specific example, the publication of Zhang and He [1] gives an overview of how text mining can be applied to energy materials including those for solar cells, batteries, materials for hydrogen fuels, catalysts. Similarly, this text mining process will be applied in the BIOMATDB project, where relevant information will be categorised and extracted from biomaterials data.
The general text mining procedure is divided into several subtasks, in order to convert unstructured data into structured data. The following paragraphs briefly explain the most used and common ones.
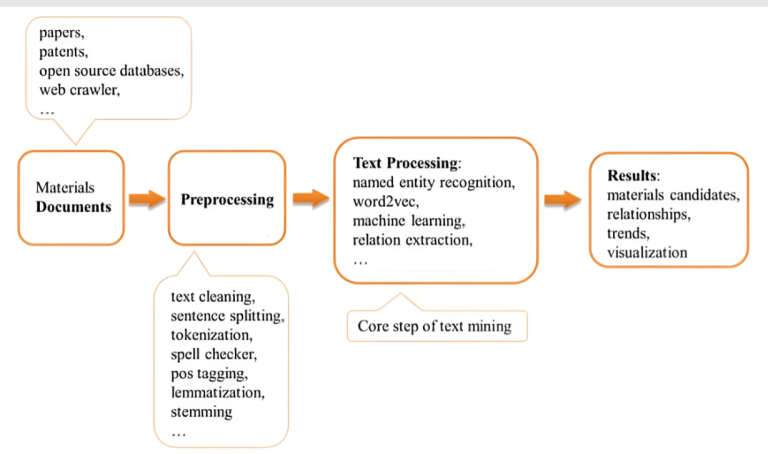
Document preparation and information retrieval: This task is the starting point and consists of enriching the database by downloading and collecting the textual data of interest, which may even come from experiments and first-principles calculations, to facilitate the material screening (Figure 1).
Pre-processing stage: The second task is generally referred to as text pre-processing and includes steps such as text cleaning, sentence splitting, tokenization, spell checking, POS tagging, lemmatization, and stemming to harmonise data and transform it into a structured form (Figure 1).
Text analysis: The next step consists of extracting relevant and useful information based on diverse systems and techniques that can classify and categorise the data and extract the relations between entities. For example, Named Entity Recognition (NER) is of particular importance in this process. This natural language processing task consists of identifying and classifying unstructured text with specific labels such as dates, names, diseases, materials, methods, costs, etc. Its application is highly necessary for further analysis such as finding the relationships between the material names and their structures, synthesis steps, properties, and performance. NER can be rule based, dictionary based, machine learning (ML) based, or a hybrid of these methods. In the materials domain, NER can be used to extract and summarise important information from the materials science literature, providing insights into inorganic material mentions, sample descriptors, phase labels, material properties and applications, as well as any synthesis and characterisation methods (Figure 1).
Another important step in text analysis is Relation Extraction, which consists of identifying and extracting relevant relationships of interest between named entities present in the text. In other words, it aims to uncover the semantic connections or associations between entities, providing insights into how different entities are related to each other. In this case, supervised, semi-supervised and unsupervised machine learning methods are commonly used, where neural networks and word embeddings (such as word2vec, Glove, fastText) facilitate this task by performing language modelling and feature learning.
At the end of these steps, a final database of relationships between named entities is constructed and available for further analysis depending on the research purpose, providing new discoveries in the energy material domain.
Authors: Miguel Rodríguez, Jan Rodríguez
References
[1]. Lei Zhang, and Mu He. “Text Mining for Energy Materials.” J. Res. Sci. Eng 4 (2022): 117-130. Available from: https://web.archive.org/web/20220515080240id_/http://www.bryanhousepub.org/src/static/pdf/JRSE-2022-4-3_24.pdf
Keywords
Text Mining, Materials Information Extraction, Text Preprocessing, Machine Learning.